BinaryRelations Approach
Andrew Girow
Copyright © 1996 Andrew Girow. All Rights Reserved.
1. INTRODUCTION
Traditional database management systems (DBMSs) support a
data model that consists of a collection of named records,
each attribute of which has a specific type. This model is
not adequate for future data processing applications.
Records provide an excellent tool to process information that
fits a certain pattern. Other kinds of information do not fit
as well into record structures. Some information cannot be
presented in records. Other information can be presented in
many ways.
Models that provide additional structures around the records
(relational, hierarchies, networks, object-oriented) overcome
some of the functional limitations. None of them overcome all
the limitations. Furthermore, by building on top of record
structures, they retain all the underlying ambiguities.
2. "RECORD-BASED" OBJECT DATABASE MODEL
By record we mean here a fixed sequence of field values,
conforming to a static description. The description consists
mainly of a name, length, and data type for each field. Each
such description defines one record type. The remarks apply
to any data model based on this kind of construct. This
cleanly includes the traditional hierarchical, relational,
network and object-oriented models.
2.1 RECORD STRUCTURES
The records of a given type describe a set of things in the
real world (for example, employees). Record structure fits
best when the entire population has the same kinds of
attributes (for example, every employee has a name, address,
department, salary). While exceptions are tolerated, the
essential configuration is that of homogeneous populations
of records, all having the same fields.
Although commercial data processing naturally focuses on
areas that fit this pattern, the pattern does not always
hold. In many cases although a certain group of individuals
constitutes a single "kind" of thing, there is considerable
variation in the facts relevant to each individual in that
set.
This situation is fairly common. The employees of a
multinational corporation might not all have social security
numbers. Some books do not have ISBN.
2.3 RECORDS AND INFORMATION CONCEPTS
For information modelling purposes, one has to account for
such concepts as entities and relationships.
There is a natural to identify entities with records. A
record is a unit of creation and destruction, as well as of
data transmission. Records are classified into types as
entities are.
Is there 1:1 correspondence between entities and records? No.
Entities are not always single-typed. There is some
difficulty in equating record types with entity types.
It seems reasonable to view a certain person as a single
entity. Such an entity might be an instance of several entity
types, such as person, employee, customer, stockholder,
taxpayer, student. It is difficult to define a record type
corresponding to each of these, and then permit a single
record to simultaneously be an occurrence of several record
types.
Note that we are not dealing with a simple nesting of types
and subtypes as in object-oriented models. All employees are
people, but some customers and stockholders are not.
Subtypes are not mutually exclusive: some people are
employees, some are stockholders, and some are both.
To fill well into a records discipline, we need to perceive
entity types as though they did not overlap. We should think
of customers and employees as always distinctive entities,
sometimes related by a “is the same person” relationship. One
has to be very careful about the number of entities being
modelled. If an employee is a stockholder, there will be two
records for him; is he two entities?
Even within a single type, there may be facts that are
relevant to some occurrences and not others.
A binary relationship is a fairly simple concept: a named
link between two entities. However there are about half dozen
ways to implement binary relationships in record structures.
There is no effective way to characterise "attributes", or to
distinguish them from relationship. In fact, the most
dominant correlate seems to be with record structures: if a
field value is the key (reference or pointer) of some record,
then it represents a relationship; otherwise it is an
attribute. So we have this need to map things into records
seems to be the main force motivating a distinction between
attributes and relationships.
3. BINARY RELATIONS APPROACH
We have outlined a number of ways in witch record structures
fail to model semantics of information accurately and
unambiguously.
Binary relations models are more directly based on semantic
concepts, for example, entities and the network of
relationships among them, rather than on recordlike
structures. Such models tend to be more functionally complete
in their information processing capability, and more precise
in their semantic modelling.
In this chapter some concepts of Binary Relations Approach
are given. They are described in several places in literature
[1],[2],[3],
[4].
3.1 BASIC CONCEPTS
The objects which are part of the real word are called entities
. Entities are associated with each other according to certain
rules (relationships).
These observations allow us to construct a model of the real word,
containing the classifications of entities and rules. To do so, we will
form sentences - binary relations. This collection of
sentences will be called a database schema.
Specific binary relations which at a specific instant in time exist in
the real world, will be recorded in a database.
In general, a binary relation consists of two terms
a key and a valuewhich refer to
entities, and a predicate an access function which
connects the terms by saying something about them.
example: "A person works in an enterprise."
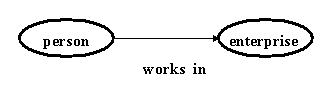
Picture 1.
In general, an access function is a function which maps one object
into the powerset of another (the set of all subset).
While defining a relation one gives the key and value object types
involved, and one defines the access function and gives information
about its cardinality. When the cardinal of an access function is
unique then it is a function. When the cardinal of an
access function is multiple then it is a multiple-valued
function.
For the schema in Picture 1 we can write:
relation(works_in, person, enterprise, unique),
where
works_in name of binary relation (access function),
person key object
enterprise value object
unique cardinal
3.2 DATABASE SCHEMA
A database schema is a collection of binary relations definitions.
In Picture 2, we present a simple representation of the binary
relations among important types of objects in a corporation.
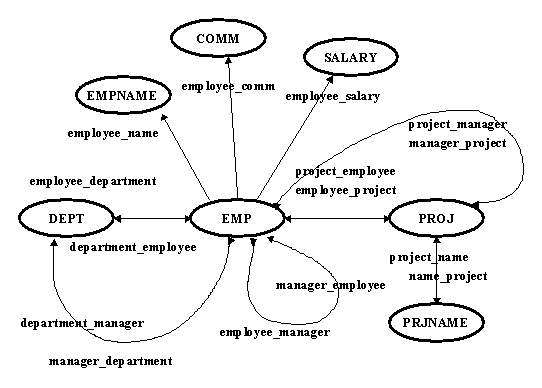
Picture 2. Hypothetical information structure
The ovals contain object types and the lines indicate how the object
types are related.
In the Binary Relations Approach the type system is very simple and
powerful. Objects types are divided into base types and abstract
types. Base types are those, like int, char, float, etc that are
implemented in a language such as C. Abstract types generally
correspond to what are often known as ABSTRACT DATA TYPES
(ADT). One can only operate on such types through access
functions (binary relations). Abstract types are created whenever the
user creates binary relations.
After the defining abstract object types you can generate new types
and build different hierarchies of types. In general you can use:
generalisation, aggregation, and
association for building hierarchies.
We demonstrate it for our corporate information structure. We shall
start from an empty database schema and add types step by step.
1. We inform the database that "Employees have commitions, names
and salaries". For it we create an EMP (EMPLOYEE) type as an aggregated
type.
relation( employee_comm, Oid EMP, Float COMM, unique)
relation( employee_name, Oid EMP, String EMPNAM, unique)
relation( employee_salary, Oid EMP, String SALARY, unique)
2. We inform the database that "Some of employees have subordinates".
For it we create a MANAGER OF EMPLOYEES type as a subtype of EMPLOYEE.
relation( manager_employee, Oid EMP, Oid EMP, multiple)
relation( employee_manager, Oid EMP, Oid EMP, unique)
3. We inform the databases that "Employees work in departments. One
employee can work in more than one department". For it we create an
DEP (DEPARTMENT) type using association with EMPLOYEE.
relation( employee_department, Oid EMP, Oid DEP, multiple)
relation( department_employee, Oid DEP, Oid EMP, multiple)
4. We inform the database that "Some of employees are managers of
departments". For it we add a MANAGER OF DEPARTMENT type as a subtype
of EMPLOYEE.
relation( manager_department, Oid EMP, Oid DEP, unique)
relation( department_manager, Oid DEP, Oid EMP, unique)
5. We inform the database that "Some of employees are members of
projects". For it we add a MEMBER OF PROJECT type as a subtype of
EMPLOYEE.
relation( employee_project, Oid EMP, Oid PROJ, multiple)
relation( project_employee, Oid PROJ, Oid EMP, multiple)
6. We inform the database that "Projects have names". For it we add
a PROJ (PROJECT) as an aggregated type.
relation( project_name, Oid PROJ, String PRJNAME, unique)
relation( name_project, String PRJNAME, Oid PROJ, unique)
7. We inform the database that "Some of members of projects are
managers of projects". For it we add a MANAGER OF PROJECT type as a
subtype of EMPLOYEE.
relation( manager_project, Oid EMP, Oid PROJ, multiple)
relation( project_manager, Oid PROJ, Oid EMP, unique)
Note that we are not dealing with a simple nesting of types and
subtypes. Subtypes are not mutually exclusive: some employees are
department managers, some are project managers, and some are both.
3.3 BINARY QUERY LANGUAGE
Binary Query Language (BQL) is an SQL style language. BQL provides
easy access to binary relations. We use the database described above
and give an overview of the most relevant features.
As explained above, we can "navigate" from objects to objects using
binary relations. To do this in BQL, we use "accessfunction()"
notation which enables us to access abstract objects, as well as to
follow relations. For instance, we have a Department "dep" and want
to know a name of the manager of the department.
The BQL query is:
employee_name(manager_deparment(dep))
This example used unique binary relation. Let us now look at multiple
relations. Assume we want the names of the employees of the manager
"empmgr". We cannot write: employee_name(manager_employee(empmgr))
because the result is a binary relation between empmgr and the set of
employees names. We use the select-where clause as in SQL.
select employee_name(manager_employee(empmgr))
The result of this query is a binary relation:
relation(manager_employee_name, EMP, EMPNAM, multiple).
Now we have means to navigate from an object towards any object
following any relation.
Of course, the "where" clause uses to define any predicate to select
the data. For instance, we want to restrict the previous query. We
are only interested in the employees who do not take part in a
Project "prj". And the query is:
select employee_name(manager_employee(empmgr))
where manager_employee() <> project_employee(prj)
In the select-where clause, relations which are not directly defined
can also be used. For instance, to get the employees having the given
salary we use "inverse" keyword.
select inverse(employee_salary())
where employee_salary = 30000.
3.4 METHODS
The notation for calling a method (function) is exactly the same as
for accessing an object or following a relation. This flexible syntax
frees the user from knowing whether the property is stored (a binary
relation) or computed (a method). For instance, to get the sum of
emloyees salary we write:
select sum(employee_salary())
Of course, a method can return a binary relation. For example, we
want only first two names of the employees of the manager "empmgr".
We write:
select employee_name(first_two(manager_employee(empmgr)))
Although "first_two" is a method we "traverse" it as a relation.
3.5 POLYMORPHISM
A major contribution is the possibility of manipulating
polymorphic collections of objects. We can carry out generic actions
on the objects of these collections. For instance, all the queries
against EMPLOYEE extent dealt with MANAGER OF DEPARTMENT, MEMBER OF
PROJECT, MANAGER OF PROJECT.
4. CONCLUSIONS
We have outlined a number of ways in witch record-based models
fail to model semantics of information accurately and
unambiguously.
Binary relations, are more directly based on semantic concepts rather
than on recordlike structures. Such models tend to be more functionally
complete in their information processing capability, and more precise in
their semantic modelling.
The Binary Relations Approach was implemented in BinaryRelations Library
for C and C++. BRL is not a full featured DBMS. It does not support all
ideas of the Binary Relations Approach. BRL is however a small, fast and
reliable engine. BRL provides basic tools for using binary relations
in C and C++ programs.
[1] J. R. Abrial. Data semantics, in
Database Management Systems, J.W. Klimbie and K. L. Koffeman,
eds., North Holland, New York, 1974.
[2] M. E. Senko. DIAM as a detailed
example of the ANSI SPARC architecture, in Modelling in Data Base
Management Systems, G.M. Nijssen, ed., North-Holland Publishing,
Amsterdam,1976.
[3] A. Girow. Objects and Binary Relations,
in Object Currents Vol. 1, Issue 6, SIGS Publications, NY, 1996.
[4] A. Girow. Binary Relations Approach to
building Object Data Model, in Object Currents Vol. 1,
Issue 11, SIGS Publications, NY, 1996.
Copyright © 1996 Andrew Girow. All Rights Reserved.
Last updated: November 11, 1996