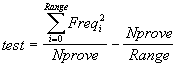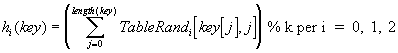Ho eseguito vari test per verificare:
I tempi di costruzione della tabella al variare della funzione Hash,
del numero delle chiavi e di r
Il numero dei backtracking ed il numero dei ricalcoli.
Sono stati fatti anche test utilizzando tecniche di backtracking
"interno", ovvero nella funzione CreaHash stessa, ma non sono riportati in
quanto non significanti: i tempi ottenuti non sono affatto accettabili, anche se è
presumibile che quando il numero delle chiavi cresce di molto oltre il mio limite massimo
(16000) potrebbe essere utile considerare un backtracking "interno" quando si
arriva alle ultime K-Liste. Cominciamo con i test effettuati con la Hash 3.
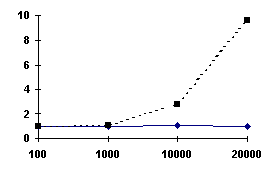
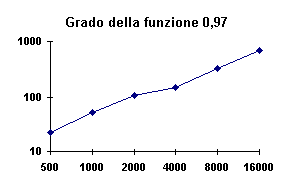
Figura -4 - Tempi (s) di creazione tabelle Hash con r minimo
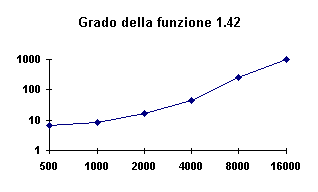
La funzione presenta un andamento non del tutto lineare: grado = 1.42,
ma dal grafico sembra evidenziarsi un andamento quadratico che fuori dalla scala
logaritmica indica un andamento esponenziale. Questo è dovuto in parte al numero delle
prove, in parte alla variazione di r ed in ogni caso il tutto è attribuibile solo al
numero di backtracking esterni effettuati, in quanto il tempo che ogni chiamata a CreaHash
cresce linearmente come si vede nella figura successiva. D’altra parte con la
variazione di r verso il valore minimo è ragionevole aspettarsi un aumento dei tempi.
Figura -5 - Tempi necessari per una chiamata
a CreaHash (ms) con r minimo
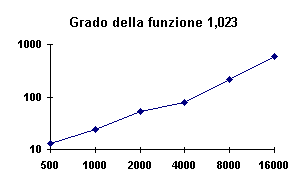
Oltre al tempo per creare la tabella ho contato anche il numero di
chiamate a CreaHash ed il numero di ricalcoli (vedi Tabella 3*).
I tempi rappresentati nella figura di sopra sono quelli necessari per effettuare una
chiamata a CreaHash e quindi si vede che, in condizioni ideali o comunque con un numero di
prove infinito, la crescita è nettamente lineare (grado = 1,023), anche se notiamo uno
scostamento per valori elevati a causa della variazione di r che inizia farsi sentire. Le
stesse prove sono state fatte utilizzando un valore di r costante ed elevato pari ad n/2.
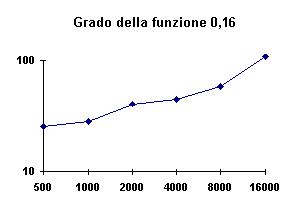
Figura -6 -
Tempi (ms) di creazione della tabella Hash con r costante
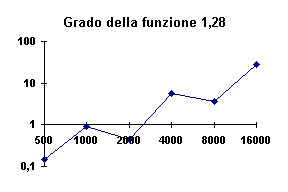
Il grado di questa funzione è circa 1,28 e quindi non molto lineare,
ma questo è dovuto probabilmente a causa di due valori molto incerti, per 2000 e 8000
chiavi. In ogni caso la costanza di r ha portato il tutto verso una maggiore linearità
rispetto alla Figura V-4 *
Figura -7 - Tempi (ms) di chiamata della
funzione CreaHash con r costante
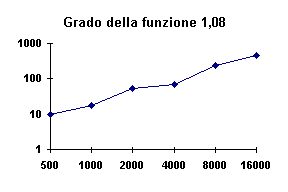
Si nota che sono gli stessi della Figura V-6 (grado di questo 1,08).
Anche per questo caso è stato calcolato il numero di backtracking e il numero di
ricalcoli: vedi Tabella 1 *. Di seguito vediamo come quando r
tende al valore minimo i tempi salgono bruscamente.
Figura -8 - Tempi(s) searching al variare di
r con n costante
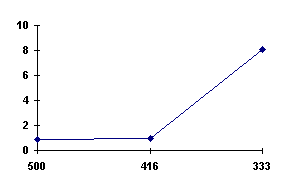
Questi dati fanno riferimento alla Tabella 5, *.
Come si può notare avvicinandosi al valore minimo i tempi subiscono una forte impennata.
Vediamo adesso i tempi globali attraverso alcuni grafici cumulativi in scala logaritmica.
Figura -9 - Tempi (ms) cumulativi nelle varie
fasi
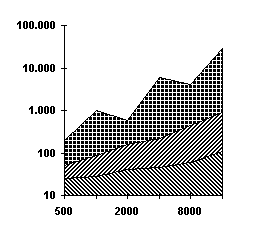
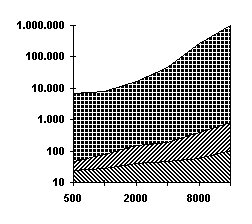
Qui possiamo notare in scala logaritmica i tempi delle tre fasi: dal
basso verso l’alto troviamo Mapping, Ordering e Searching. Si può notare che
c’è un ordine di grandezza di differenza tra i due grafici che hanno rispettivamente
r costante pari ad n/2 e r minima. Notiamo altresì che la velocità con cui crescono i
tempi è sempre maggiore: si va dalla quasi costanza del Mapping (grado = 0.18)
fino alla scarsa linearità del Searching (grado = 1.3 circa). Questi grafici
riassumo i dati della Tabella 6* e della Tabella 7*.
Detto ciò, considerando che i tempi per il Mapping e l’Ordering
non dipendono dalla funzione Hash vediamo quali risultati otteniamo con le funzioni
Hash 1 ed Hash 4 nel caso specifico in cui r è numkey/2 e confrontiamo con gli
stessi dati ottenuti dalla Hash 3. Vedremo che i risultati di cui al paragrafo 7 * troveranno conferma.
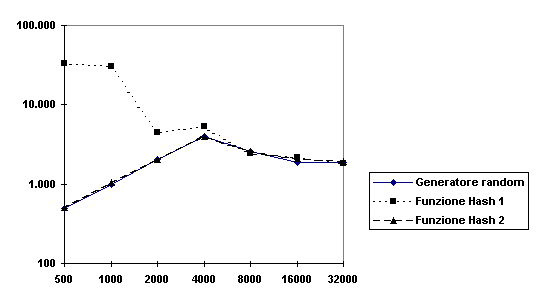
Figura -10 - Confronto tra
funzioni Hash
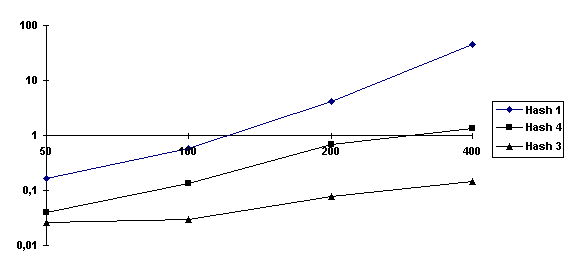
Ricordo che la Hash 3 è data dall’Espressione V-6*, la Hash 4 dall’Espressione V-5* e la Hash 1 dall’Espressione II-1*. Notiamo che la crescita della Hash 1 sembra essere
quadratica nel grafico, cioè esponenziale nella realtà, in ogni caso il grado del
polinomio che si ottiene è 3,27. Le altre due crescono abbastanza linearmente sul
grafico. Tuttavia questo per la Hash 4 corrisponde ad un grado pari a 1,67 e quindi
possiamo parlare di crescita quadratica. Per la Hash 3 otteniamo un grado 1,12 abbastanza
lineare: anzi è il migliore ottenuto e questo conferma che se r è costante la crescita
è poco più che lineare.