Reprinted
from the paper presented during the 1969 Fall Joint Computer Conference
held at Last Vegas, NV. Since the JCC no longer exists, reproduction rights
has been sought and obtained from Dr.
R A Greenes and Dr. G O Barnett.
The OCR process may have introduced errors.
Other than a spell check, the content of the original document has not
been changed, although the document has been formatted.
A System for Clinical Data Management
by R. A. GREENES, A. N. PAPPALARDO,
C. W. MARBLE, and G. O. BARNETT
Massachusetts General Hospital
Boston, Massachusetts
Introduction
The application of computers to the delivery of patient care is more a
problem of "data management" than of "data processing." Although
calculations and interpretation of data are often required, of much greater concern are
the problems involved in the collection, communication, co-ordination, and presentation of
information. As the process of delivery of medical care becomes increasingly complex, and
involves increasing numbers of professional and non-professional personnel, responsibility
for achieving the continuity and comprehensiveness that is essential to medical care seems
to rest heavily on the development of appropriate computer-based data management systems.
Such systems may further provide the primary feasible means by which quality control,
auditing of the medical care process, and research into the diagnosis and treatment of
disease can be achieved.
These functions now are dependent on the use of the patient medical
record, although they are fulfilled only to a minimal extent by it. Despite changing
functions and increased demands on it, the medical record has changed little in form over
the past century. Medical records possess no organization by diagnostic or therapeutic
problem; notes relevant to a particular aspect of a patient's health may be accessed only
by leafing through an entire volume. Terminology is not standard, data is not organized in
well-defined formats, and notes are often illegible. As a consequence, the objective of
using the computer for clinical data management is gaining considerable impetus.
This paper will describe a number of criteria which the authors have
found to be important in the design of systems for clinical data management, and a novel
system which has been implemented to meet these requirements. The system to be described
has been in operation for over a year. The extent to which it has proved useful has led
the authors to believe that the criteria defined have general applicability for clinical
data management. In the discussion to follow, the term "clinical data management
system" refers to a timeshared computer system which supports on-line input, inquiry,
and retrieval of clinical information from a central data base.
Design and implementation
The internal design of an information system dictates constraints on
the external attributes of such a system. The characteristics that must be resolved
include the number, priority, and level of responsiveness of the users, both active and
inactive; the ratios among CPU time, connect time, and input/output time; the structure,
magnitude, and timeliness of file information; the profile of application programs in
regard to size, type, and interactiveness; user requirements for development and service
modes of operation; and finally, the overall economic justification for the system.
High level programming language
One of the most time-consuming aspects of the development of
information system programs involves the optimal interfacing of the system with its users
in a particular application area. This requires much attention to human engineering, and
repeated modification and revision of programs. The implementation of clinical data
management applications has generally begun on relatively small computers. This has, in
many cases, been necessary because development was a gradual process and started with
limited objectives. Since high level languages have not typically been available on small
machines, most programming has been done in machine language.
The expense and inefficiency of writing, debugging, and modifying such
programs have been serious obstacles to active research and development. A few clinical
data management systems have used large general purpose computers which could provide much
increased flexibility. However, the overhead of a large operating system on a major
computer has often seemed excessive, because of the rather small amount of processing
involved in many of these applications. Furthermore, because of the reliability
requirements of a clinical data management system, modularity and duplication of hardware
is desirable and often essential. Because of the expense entailed by hardware redundancy,
this is typically feasible only with inexpensive, minimal equipment configurations.
The MGH Utility Multi-Programming System (MUMPS) is a compact
time-sharing system on a medium scale computer, dedicated to clinical data management
applications. It is currently implemented on a PDP-9 (Digital Equipment Corporation) with
24,000 words of 18 bit memory and a Burroughs fixed head disk with three million
characters of storage capacity. A set of terminal scanners is used to inter" face to
remote devices: teletypes, buffered display scopes, line printers, card readers, and A/D
converters. Both memory size and peripheral storage capacity can be expanded in the
system. In the current version, 16 users may run simultaneously.
All application programs in this system are written in a high-level
interpretative language, a distant ancestor of which is JOSE, 1 developed at the Rand
Corporation in 1964. It has also been influenced by related languages such as STRINGCOMP
(developed by Bolt, Beranek and Newman, Inc.), and FILECOMP (specified by Medinet Division
of General Electric Corp.). The MUMPS language allows the programmer to write a program,
debug it, edit it, run it, and modify it concurrently during an interactive session at a
console. The interpreter itself is a part of the executive system and is re-entrant. The
total space taken up by the time-sharing monitor, the I/O monitor, buffers, and re-entrant
interpreter is currently about 8,000 words of memory. The time-sharing and I/O monitors
have been specifically tailored to work efficiently with the interpreter. No attempt has
been made to accommodate machine language user programs. All active users are assigned
partitions of core memory. Activating a program
consists of finding an available partition and bringing the program into it from disk; as
long as it remains active, it occupies its partition. Core and disk storage allocation are
depicted in Figure 1.
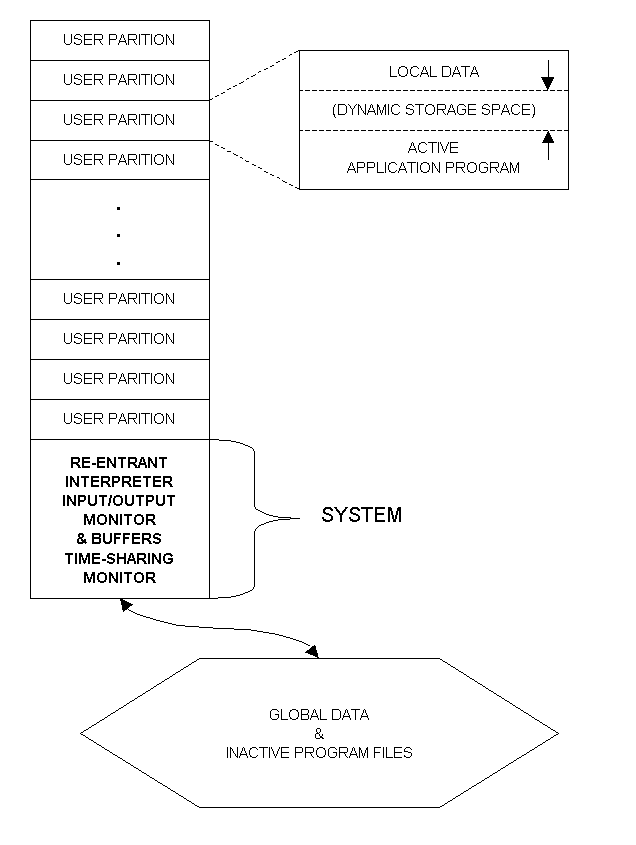
Figure 1—A schematic diagram of the core memory allocation of the
MUMPS system and user partitions. A single partition is expanded to show its internal
structure. The use of secondary storage (disk) for global data and inactive programs is
represented.
The basic orientation of the language is procedural, much as FORTRAN
and ALGOL. The largest unit of a program is a group of statements called a
"part" indicated by an integer part number. A single line or statement of the
program is a "step"; it is identified by a step number consisting of a decimal
fraction appended to the part number. Multiple commands may be entered in a single step
and executed one after another. A conditional statement which when evaluated has a false
value will, however, cause the rest of the commands in that step to be ignored. Commands
may be stated in a long mnemonic form, or for the experienced user, in a much more compact
form in which only the first letter of the command is used. A statement preceded by a step
number is considered to be in "indirect" or "program" mode, and is
stored to be executed as part of a program. A statement without a step number is in
"direct" mode, which indicates that it is to be executed immediately after it is
entered from the user terminal.
Interface flexibility
Clinical information about a patient derives from a variety of sources
-- the patient, the attending physician, coonsultants, the radiologists, the clinical
laboratory, etc. Problems of using the computer to obtain information from each of these
sources have begun to receive attention. Perhaps the most widespread activity of this type
has been the development of systems for clinical laboratory information processing.
2,3,4,5
With the exception of laboratory data, which is either numeric or
simple text, much of the clinical information in the medical record is generally recorded
in narrative or free text form. Most investigators are convinced that natural language is
not in general suitable for computer record keeping applications, except perhaps in
certain circumscribed areas with limited vocabulary and syntax.6,7 As a result,
there is a significant amount of work currently being devoted to the development of
methods for structuring this narrative data.8,9,10 It is generally recognized
that this may be best achieved by introduction of new ways of capturing such information,
e.g., entry of data by use of check lists, forms, or direct user-computer dialogue.
Interactive dialogues for the capture of narrative data may be based on hierarchical
organization and presentation to the user of the subject material. Any particular topic
may then be pursued to an arbitrary depth, by means of a succession of increasingly
discriminating selections by the user from the options presented. A variety of programs
for interactive acquisition of clinical data have been developed, and have generated needs
for special terminals, display v formats, and conversational languages. Conversational
programs have, for example, been devised for the on-line acquisition of a patient's
medical history.11,12 Other systems aimed primarily at the physician have been
designed for the purpose of entry of physical examination notes,13 the
recording of progress notes, or the generation of X-ray reports by the radiologist.14,15
In the development of such applications, the emphasis is placed primarily on the interface
(hardware, software, and environmental) of the system with the individuals who have to use
it.
As the potential of clinical data management systems is recognized,
they will be called upon to fulfil a diversity of output functions, e.g., the display of
reports or summaries, organized chronologically or topically, the production of tables or
graphs. Information obtained by dialogue must often be translated into more precise
medical terminology, or compacted into coded representations. Flexibility in output and
presentation of information, as well as in its acquisition, is essential.
The philosophy of MUMPS has emphasized the need for ease in interfacing
and adapting programs to the requirements of the application. Programs written in the
interpretative language do not require any compiling or assembling. Error comments during
execution are typed out at the user's console, and allow quick recovery, modification of
the program, and re-execution of it. All debugging and modification is done in the same
language in which the program is written and can be done entirely from the user terminal.
This makes modification especially convenient, particularly in a service environment where
the trouble shooting necessary to interface a program with an application area is a time
consuming process. The MUMPS environment allows a programming session to take the form of
a conversational dialogue between the programmer and the terminal device, thus minimizing
the user's time in programming a problem, the computer's time needed in checking it out,
and most important, the elapsed time required to obtain a final running application
program.
Text handling capabilities
The complexity and variety of data that must be handled in a clinical
information system impose a number of requirements on the system. A considerable amount of
information that is input is in the form of text strings of variable length. The
processing of input often requires syntax checking or limit checking. String comparisons,
extractions, and concatenations need to be performed. When special driver languages or
monitor subsystems are employed to control dialogues between the user and the computer,
string processing capabilities are mandatory. Most existing higher level languages do not
provide the needed combination of algebraic and Boolean expression handling capabilities
with the ability to handle string information.
The MUMPS language has been designed to meet this need. In addition to
algebraic and Boolean processing, a MUMPS program can perform string extraction,
locations, comparisons, and checking of syntax and form of information. These features are
illustrated in Figures 2 and 3. Figure 2 shows a portion of a program written in MUMPS to
read a hospital unit number from a Teletype (i.e., entered by a user), to check its
syntax, and to reject any improperly formatted responses. Figure 3 shows statements in a
program for the clinical chemistry laboratory, which permit entry of a test name and its
result. Checks are made on the legality of the test name and the reasonableness of the
result. Some of the interactive editing capabilities are shown in the figure.
Þ WRITE 1
1.10 READ !,"UNIT NO. ".X
1.15 IF ‘X:3N"-"2N"-"2N TYPE "
ILLEGAL" GOTO 1
Þ
DO 1
UNIT NO. 123-45-678 ILLEGAL
UNIT NO. 12-345-67 ILLEGAL
UNIT NO. 123-456-78 ILLEGAL
UNIT NO. 123-45-67
Figure 2—A portion of a MUMPS program
to input a seven digit unit number from the teletype (accomplished by step 1.10. The value
entered is stored as the variable named X; a cheek is made that X has the correct form,
i.e., 3 digits, followed by a hyphen, 2 digits, a hyphen, and 2 more digits (step 1.15).
Improper values cause an error message, and request of a new value. The WRITE command
lists the statements. The DO command causes execution, which is illustrated. (In this and
other figures, user input is underlined to distinguish it from the response of the
computer.)
Terminal device flexibility
An important feature of the language is its input/ output scheme, which
permits programs to be written independently of the particular device for which one is
programming. One may use any device for which the hardware system has been appropriately
interfaced by merely assigning a device number to a system variable indicating the device
to be utilized. This makes it possible to generate a report on a display scope, for
example, and then to use the same program to type out the report on a typewriter, merely
by changing, during execution, the value of the device number assigned to the input/output
variable. Formatting and control of position on a page are made very simple by utilization
of special format characters and variables indicating current position and line spacing.
Multi-user access to a central data base
A major requirement of a clinical data management system is that the
information stored be accessible to a variety of users concurrently. Access may be from a
variety of terminals, by a variety of programs in the system, at varying frequencies.
Among the possible purposes for accessing a file might be to report a laboratory result,
to enter an X-ray impression, to record a progress note, or to enter a specific inquiry.
Although many of these activities occur independently, they must share a common data base.
Nevertheless, manipulation of the data base must occur without time sharing conflict, such
as might occur if two users were to update a portion of the data base simultaneously.
Without special provision, this might result loss of information.
Þ
WRITE 2,9
2.05 SET
DCT="CA,P,FHS,CHOL,TP,NA,K,CL,CO2,SGOT,LDH,VDB,BUN,CRE"
2.10 READ !,TEST: ", TES
2.20 FOR I=1:1:14 IF $PIECE(DCT,I)=TES QUIT GOTO 2.3
2.25 TYPE " ???" GOTO 2.1
2.30 ASK !,"RESULT= " ,RES GOTO I+3
2.40 READ " PROB. ERROR...OK? ",X IF 'X["Y"' GOTO 2.3
2.50 DO 100 TYPE ! GOTO 2.1
9.10 IF RES>160!RES<120 GOTO 2.4
9.20 GOTO 2.5
Þ
DO 2
TEST MA ???
TEST NA
RESULT= 125
TEST:___
? 2.10 IOINT
Þ
9.1 IF RES>150!RES<130 GOTO 2.4
Þ
DO 2
TEST: NA
RESULT= 125 PROB. ERROR...OK? Y
TEST:
Figure 3—A section of a MUMPS program that might be
used in a clinical chemistry laboratory information system. Step 2.05 sets the variable
DCT to the list of test determinations that are valid for this particular laboratory. Step
2.10 then accepts a test name from a technician. The $PIECE function in step 2.20 then
extracts substrings (between commas) from DCT and compares them to the variable TES whose
value is the test name entered. It does this repeatedly for values of I =1,. . .,14 until
a match is found; at this point the iteration is terminated and execution continues at
step 2.30. If no match is found, an error comment is printed (step 2.25) and step 2.10 is
repeated. Step 2.30 accepts a test, result, and goes to a part in the program dependent on
the particular value of I for which the match was found.
Part 9 illustrates a specific check for results entered
for the test name, NA (in which case I = 6). The result is compared to prescribed limits,
in step 9.10, and if it exceeds either limit, control goes to step 2.40. Here the user is
asked to verify the value. The user's response is inspected to see if it contains a
"Y", in which case a YES response is implied. Otherwise, a new result is
requested, in step 2.30. If either the user verifies it, or the result is within limits
set by step 9.10, control goes to step 2.50. Step 2.50 calls part 100 to file the value
and then returns to step 2.10.
The DO command causes execution, which illustrates
operation of the program. Note that the user has interrupted the program from his teletype
(indicated by the "? 2.10 JOINT" error comment, showing where the interrupt
occurred). In this case, a programmer has decided to edit the program to make the limits
for a sodium determination more stringent, by retyping step 9.10. The program is then
re-executed.
Efforts to develop specialized clinical data management applications
are still relatively primitive. There have been very few concerted efforts devoted to the
general problem of management of medical record data, the development of integrated
patient data files, and the implementation of systems for long term storage and retrieval
of this data.16,17 Among the difficulties faced by the few developmental efforts that have
been undertaken have been the lack of generality in their approaches, and the reliance on
highly specific programming languages, file structures, and file handling routines.
MUMPS provides application programs with the ability to create and
utilize their own "local" data, as well as to manipulate "global"
data, shared by other programs in the system. Local data utilized by a program is
referenced symbolically, and space for it is allocated as needed. Local data is that set
of variables established within the domain of a particular program, and available and
defined only within that program. The data actually resides within the user partition, and
functions as scratch or transient data. Local arrays are assumed to be sparse or of
varying dimensions, and only subscripts for which data are defined are allocated space. A
symbolic variable used in a program may be given either a numerical value or a
variable-length string value. When it has a string value, only that space required by the
string is actually allocated. Thus for both strings and sparse arrays, the overhead of a
compiler system does not exist, in which typically maximum sizes of arrays and maximum
lengths for string variables must be allocated.
This philosophy is extended to the management of data on the random
access disk. Elements stored in data files are referenced entirely symbolically; the file
name is similar to that of a local variable name in a program. Fields in the data file are
treated as array elements and referenced by means of subscripts; subfields are referenced
by appending additional subscripts. Data files on the disk thus comprise an external
system of arrays, which provide a common data base available to all programs. The arrays
which make up this external system are called global variables, and are identified by
global array names. A global name (or file name) consists of the character up-arrow (^)
followed by at least one alphabetic character. The form of the subscript portion of an
array reference consists of an arbitrary number of numeric expressions separated by commas
and enclosed by parentheses.
To avoid time-sharing conflicts, a program may prevent other programs
from having access to one or more global arrays which it is in the process of altering in
some way, by the use of the command OPEN. The argument of OPEN may be one array name or a
list of array names. OPEN prevents any other program from altering data in any of the
specified arrays. The effect of OPEN is cancelled when the program ends or at the
occurrence of the command CLOSE, which does not require any arguments, and releases all
opened arrays to other users in the system.
Hierarchical data base organization
A most important requirement for clinical data management is the
ability to handle the several levels of structure of a medical record data base, and to
support the rather complex updating and retrieval needs of such a system. An example of a
typical patient data file, such as exists in the information system under development at
the Massachusetts General Hospital, is illustrated in Figure 4. This indicates the
typically hierarchical (tree-like) structure of the data base, which has both a topical
and a chronological organization. Most computer systems currently available do not have
the ability to utilize hierarchical file organizations conveniently.
The global array facility in MUMPS has been designed to meet this need.
The structure of global arrays is hierarchical, and any node within the array tree may
possess a numeric or string data value and/or a pointer to a lower level in the tree. Data
may be stored at any level, and there are no constraints to the dimension or the size of
the array. In addition the quantity and magnitude of subscripts for an array are dynamic,
so that not only may the content of an array change during usage, but also its structure
may vary.
Since modification of content and structure of a global array may be
caused by a variety of programs in the system, a particular program must sometimes examine
the current configuration of an array before attempting to access or update it. MUMPS
provides a set of global array functions to determine the type and structure of a global
array. These functions permit the programmer to locate the nodes where information is
stored within an array, and nodes within the array which are empty and thus available for
data storage.
The storage of data into an array is accomplished solely by the
assignment command, SET. Consider the following statement:
SET ^APR(UN,NAME)="JOHN DOE",^APR(UN,AGE)=34
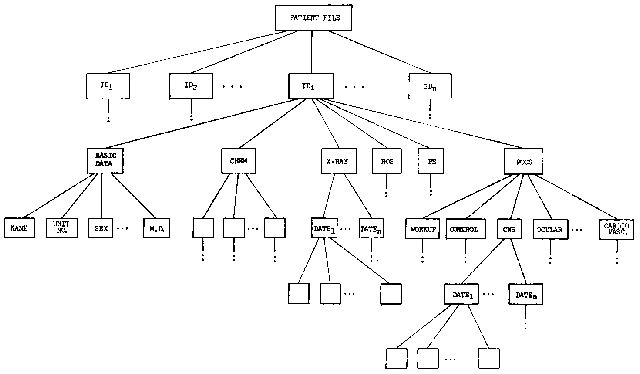
Figure 4 -- A tree-structured
patient data file, indicating: (1) the use of certain levels in the tree to group
information in specific topics, e.g., basic identifying and administrative data, review of
systems, physical examination, and (2) other levels to group information into sets which
differ by date or by some other sequencing field.
Assume the global array name ^APR is reserved for the active patient
record file. Each patient in the file is accessed through his hospital unit number, in
this case, a local variable UN. Both NAME and AGE are also local variables whose values
indicate particular categories represented by subscripts at the second level of the array.
This statement then assigns the string value "JOHN DOE" and the numeric value 34
to the specific second level categories name and age respectively. Subsequently, a
statement such as:
SET ^APR(UN,CHEM,N) = DATE.",".TEST
might define the Nth laboratory test in the chemistry lab with the
double field entry of the date concatenated (by means of the dot operator) with a comma
and the test name.
Retrieving data from global arrays is no different from retrieving data
from local arrays. Both consist of ascertaining the value of a subscripted variable by
using it within a numeric or string valued expression. The statement:
TYPE " THE AGE OF ",^APR(UN,NAME)," IS
",^APR(UN,AGE)
will effect the printout:
THE AGE OF JOHN DOE IS 34
To print out a list of a patient's laboratory tests (assuming
^APR(UN,CHEM) is the total number of tests defined) the following statement might be used:
FOR I=1:1:^APR(UN,CHEM) TYPE ^APR(UN,CHEM,I)
The KILL command when applied to a specific node in a global array,
prunes the array tree at that node. Any data value and/or array pointers to lower level
nodes are removed, and that node reverts back to an undefined status. The statement KILL
^APR(UN) would delete all information for the patient defined by the local variable UN.
Included in the global array syntax is the "naked" global
variable. The form of the naked variable consists of the up-arrow followed by a subscript
enclosed in parentheses. This notation is equivalent to the last previously used global
array reference except that the value of the last subscript is replaced with the value of
the subscript in the naked variable. For example, the statement:
TYPE " THE AGE OF ",^APR(UN,NAME," IS ",^(AGE)
is equivalent to the example cited earlier.
MUMPS requires that reference to all file information be done
symbolically, in the syntax of hierarchical global arrays. This replaces the classical
manner of sequentially accessing record files on secondary memory devices. Instead, an
attempt is made to logically map the content and structure of the tree-like data arrays
into the physical storage medium of the system. The general technique is to map logical
information at a specific level of an array into fixed size blocks chained together
linearly to contain all the data values stored at that level, and all pointer which link
it to the chains of the next lower level. The implementation of this design requires a
careful consideration of the timing and size constraints of the physical device in
relation to the overall system. The actual memory device used in the system is a large
fixed head disk. The organization of this type of disk is two dimensional, wherein any
physical block has a track and a segment co-ordinate. Initially a set of free lists are
formed which chain all blocks possessing the same segment address together. Whenever a
continuation block at the same level or a header block at a new level is required, the
appropriate block in the free list whose segment address is a few segments away is
utilized. This method makes it possible to trace down the many levels of a tree structure
required to access a datum during a fraction of a disk revolution, in addition to the
average access time of the disk unit required to reach the first level of the tree. As a
consequence, the time required to retrieve a particular datum is virtually independent of
the depth of subscripting required to specify the datum. Space is conserved by utilizing
small sized physical blocks such that at any subscript level an average of one
continuation block is required. When data is updated, care is given to repack and
sometimes reorganize the individual data elements within a chain to insure maximum
utilization of space for variable length data. Whenever a part of the global structure is
deleted, it is passed to the garbage collector routines to be disassembled from tree-like
chains back into linear chains and appended to the appropriate free lists. This is done
during periods of low CPU activity so as to avoid competition with the active programs.
Once a block of data accommodating a single level of subscripting is
referenced, it is maintained in core memory until a reference is given to a different
block by the program. Use of the naked variable then permits other data at the same level
to be referenced merely by specifying a terminal subscript, so that once a level is
reached, often no further disk access need be made to manipulate associated information.
If any data in a block is altered, it is only written back on the disk when a reference is
made to a block other than the one that is in core memory, or when a CLOSE command is
given.
Large storage capacity
The conversational environment in which a clinical 1 data management
system is designed to operate demands little computer processing power. When data is
entered, a program need only check on its legality, decide where to file it, and select an
appropriate response to the user. Generation of reports may involve manipulation of
information from peripheral storage to assemble the data needed, but only a small amount
of processing to actually format or produce the report. Large volumes of data need to be
available for low level, low frequency usage. Thus one does not need computing power as
much as the availability of peripheral storage of large capacity. Much of the data may be
potentially accessed at any time, and therefore need to be stored on a random access
device. Because of the large quantities of data that may be anticipated in such systems,
it is necessary to provide hierarchies of peripheral storage, in which the access time of
the storage device used is commensurate with the frequency or urgency of the need for
retrieval.
In MUMPS the fixed head disk provides fast random access storage,
whereas slower access requirements are currently met by three Dectape units. A large
movable head disk unit is being installed to permit intermediate access times for other
data.
Efficient Time Sharing
In a conversational data management system, programs spend much of
their time in an input/output hung status, i.e., doing disk activity or completing a
transaction at a terminal. As a result, there is again not a large demand by a program for
the central processor. In contrast to most numerical applications where central processing
power is the limiting factor, in a conversational environment the time necessary to
complete a task is often determined by the speed of the input/output equipment or the
human response time at a terminal. As a consequence of the small demand for the central
processor by an individual program, one can theoretically time share a large number of
programs. Efficiency of the use of the central processor is in this situation determined
by how rapidly the time-sharing monitor can change from one user to another. This swapping
overhead is the delay before a particular user program can run after a previous user has
quit the run state, due to an input/output hang, expiration of time slice, or termination
of its task. When the central processor is not being fully utilized, swapping overhead
tends to determine response time of the system.
TABLE I—A comparison of execution times for various numeric
processing examples
in MUMPS and FORTRAN
CPU Time (Microseconds)
Statement |
MUMPS |
FORTRAN |
MUMPS/FORTRAN
RATIO |
| FOR/DO (Iteration, per cycle) |
250 |
12* |
20.8 |
| 1 + 2 |
800 |
7* |
114.3 |
| 2*3 |
850 |
44 |
19.3 |
| 1 + 2*3 |
1050 |
48 |
21.9 |
| 1 + 2 - 3*4/5 |
1550 |
120 |
12.9 |
* These are the only operations compiled by
the PDP-9 FORTRAN Compiler as in-line code. All other operations beside integer addition
(in DO loops and arithmetic expressions) are compiled as subroutine calls.
In the MUMPS system, the use of a partitioned memory has been dictated
by the overwhelming concern for response time. As a result of partitioning, the time
sharing monitor can switch between users in minimum time without having to resort to
swapping of programs in from a drum or disk. In addition, the monitor automatically
overlays external program segments invoked by an active program. Proper linkages are set
up to return automatically to the invoking program when execution of a segment terminates.
Execution speed of an interpretative program doing pure numeric
processing may be slower by a factor of about 20 to 1 over corresponding code generated in
a compiler or assembly language system.
Table I illustrates some timing comparisons between a single user
version of the MUMPS interpreter and the manufacturer-supplied FORTRAN compiler for this
computer, for statements involving pure numeric processing activity of varying complexity.
As has been indicated above, however, few programs do pure numeric processing in a
clinical data management environment. Input/output conversion in FORTRAN and most other
compiler systems is handled in a purely interpretative fashion, and thus, for this
activity, very little difference in the performance between the two kinds of systems may
be expected. Furthermore, a significant part of the processing done by programs in
clinical data management systems involves file manipulation, or text string processing
activities; in all assembly or compiler language systems these functions are usually
handled by the use of subroutines. Therefore, the employment of an interpreter as a means
of generating calls to these subroutines rather than compiling the calls themselves
requires only a small amount of processing overhead.
The foregoing observations refer to comparisons between execution
speeds of MUMPS interpretative language statements and compiler-generated object code on a
single-user computer, with no other processes competing for the processor. More
significantly, in a data management environment, a re-entrant interpreter such as MUMPS
may provide the most economical means of achieving a highly responsive time-shared
information system. In the MUMPS system with sixteen typical users active, response times
(a most sensitive measure of efficiency in a timesharing system) are always less than a
second and usually appear instantaneous.
There are several reasons that account for this, all of which are
related to very efficient use of core storage. First, a typical program written in the
interpretative language takes up 10 percent to 20 percent of the space taken up by the
object code generated for a similar program written in a compiler language. Also, dynamic
allocation of data and efficient storage of variable length strings and of sparse arrays
are standard features of the interpreter. Thus data also take up considerably less space
in this kind of environment. In addition, since the interpreter is re-entrant, all
programs may share the same utility routines and operating system capabilities. This
contrasts rather sharply with conventional compiler language operating systems, in which
each running program must have its own copy of the necessary system routines that it will
utilize.
The significant advantage that results from the above features is that
programs take up much less space; therefore, a partitioned memory system on a medium or
small scale computer becomes feasible. Active programs are typically highly interactive,
and are therefore doing only small amounts of processing between input/output requests.
Therefore the timesharing monitor is invoked frequently to pass control from one user to
another, in order to utilize the central processor as much as possible. In a partitioned
system, swapping of the users is very rapid. In systems that use various schemes for
submerging disk or drum swapping, users that are running in a conversational mode often do
not stay in the run state long enough to submerge the concurrent swapping process.
Therefore potential CPU time is unavailable; this unused time may be on the order of 20 to
50 percent of the total amount available. The speed that results from not using disk or
drum swapping appears, in our experience, to more than offset the overhead of
interpretation, with greatly increased efficiency in the utilization of space.
CONCLUSION
The convenience occasioned by the utilization of a high level language with symbolic
referencing capability for data stored in complex tree structures on peripheral storage
has greatly simplified the development of application programs for clinical data
management. This is the only system that we know of, on a computer of medium or small
scale, which supports such extensive file manipulation, string handling, and input/output
flexibility. It is the only system we have encountered on any computer which allows all
these manipulations to occur entirely in a high level language. This system has been used
at the MGH for all of our programming research and development activities. Equally
important, because of its compactness and efficiency in this environment, we use it for
the implementation of our service programs, including a chemistry laboratory reporting
system,18 a patient history taking system, and a number of programs for
physician entry of narrative record information.
An advantage of this approach to clinical data management over the use of a large
commercially available general purpose time-sharing computer with its complex operating
system has been the increased flexibility that is possible with a specially designed
system. This increased flexibility results because the system has been built to meet
specific objectives, in contrast to having been implemented within the often arbitrary and
inefficient constraints of a general-purpose time-sharing facility. In addition, with a
special purpose system, it is possible to achieve the efficiency required for service
operation with a computer whose size and cost are well matched to the requirements of the
problem area.
BIBLIOGRAPHY
1. SHAW, J. C. JOSS: A designer's view of an experimental on-line
computing system. "AFIPS Conference Proceedings," (1964 FJCC), Vol. 26, pp. 455
464. Spartan Books, Baltimore, Maryland, 1964.
2. LINDBERG, D. A. Collection, evaluation, and transmission of hospital
laboratory data. Meth. Inform. Med. 6, 97-107 (1967).
3. PRIBOR, H. C., KIRKHAM, W. R., AND HOYT, K. S. Small computer does a
trig job in this hospital laboratory. Mod. Hosp. 110, 104-107 1968.
4. BARNETT, G. O. AND HOFMANN, P. B. Computer technology and patient
Care: experiences of a hospital research effort. Inquiry V: 51-57 (1968).
5. HICKS, G. P., GIESCHEN, M. M., SLACK, W. V., AND LARSON, F. C.
Routine use of a small digital computer in the clinical laboratory, JAMA 196, 973-978
(1966).
6. JACOBS, H. A natural language information retrieval system. Meth.
Inform. Med. 7, 8-16(1968).
7. PRATT, A. W. AND THOMAS, L. B. An information processing system for
pathology data. "Pathology Annual," VOL 1. Century Appleton, New York, 1966.
8. BARNETT, G. O. AND GREENES, R. A. Interface aspects of a hospital
information system. Ann. N. Y. A cad. Sci. (in press).
9. YODER, R. D. Preparing medical record data for computer processing.
Hospitals 40, 75-76 (1966).
10. WEED, L. L. Medical records that guide and teach New Eng. J. Med.
278, 652-657 (1968).
11. SLACK, W. V., HICKS, G. P., REED, C. E., AND VAN CURA, L. J. A
computer-based medical-history system. New Eng. J. Med. 274, 194-198 (1966).
12. MAYNE, J. G., WEKSEL, W. AND SHOLTZ, P. N. Toward automating the
medical history. Mayo Clin. Proc. 43, 1-25 (1968).
13. KIELY, J. M., JUERGENS, J. L., HISEY, B. L., AND WILLIAMS, P. E. A
computer-based medical record. JAMA 205, 571-576 (1968).
14. TEMPLETON, A. W., REICHERTZ, P. L., PAQUET, E., LEHR, J. L.,
LODWICK, G. W., AND SCOTT, F. I. RADIATE--Updated and redesigned for multiple cathode-ray
tube terminals. Radiology 92, 30-36 (1969).
15. PENDERGRASS, H. P., GREENES, R. A., BARNETT, G. O., POITRAS, J. W.,
PAPPALARDO, A. N., AND MARBLE, C. W. An on-line computer facility for systematized input
of radiology reports. Radiology 92, 709-713, 1969.
16. HALL, P., MELLNER, C. AND DANIELSSON, T. J5-a data processing system
for medical information. Meth. Inform. Med. 6,1-6 (1967).
17. DAVIS, L. S., COLLEN, M. F., RUBIN, L., AND VAN BRUNT, E. E.
Computer-stored medical record. Computers and Biochemical Research 1, 452-469 (1968).
18. KATONA, P. G., PAPPALARDO, A. N., MARBLE, C. W., BARNETT, G. O., AND
PASHBY, M. M. Automated chemistry laboratory: Application of a novel time-shared computer
system. Proc. IEEE.
Chris Bonnici
 If you have any
other document we could include here, send an e-mail to
chribonn@softhome.net.
If you have any
other document we could include here, send an e-mail to
chribonn@softhome.net.
Last Updated: 6 October 1997
The Index or Go UP
